
4 + 1 Architectural View Model: Introduction
February 27, 2019
Have you ever worked on a microservices system experiencing challenges like these?
- I've separated my system into loosely coupled microservices - why is integration between them still so hard? I'm spending all my time implementing circuit breakers, bulkheads & retry patterns when I'd rather be writing business logic!
- My autonomous microservices teams are still blocking each other from delivery - why?
- We still struggle with version incompatibilities between microservices... we've had to invest heavily in consumer driven contract testing to ensure we don't break things
- Making an update is so hard - we have to update code in multiple repositories containing our shared libraries and wait for a nuget or npm publish cycle in each of them before we can test the integration of changes
Or perhaps you're a startup who doesn't want to over-engineer their launch solution, but also doesn't want to end up with a big ball of mud, or unable to scale their system when the business starts doing well?
Either way - the "4 + 1 Architectural Views" may help.
This is the first in a series of posts about the views. Throughout the series, I hope to demonstrate how useful the 4 + 1 Views can be in understanding complex distributed systems, as well as facilitating more nuanced approaches to system design.
This first post will provide a brief introduction to each of the views, with deep dives into each view coming soon.
Origin Story
The origin and context of the 4 + 1 architectural views model is a fundamental part of the history of Software Architecture itself - a separate post explores that history.
The Views
The "4 + 1 Architectural Views" were proposed in 1995 to solve increasing challenges communicating about software architectures.
The purpose of separating the architecture into multiple concurrent views was to isolate and illustrate different aspects of the design with information specifically oriented towards different stakeholders.
Each view should:
- define the system in terms of Components, Connectors and Containers
- use appropriate styles, forms and patterns for each view
- consider applicable constraints in each view
- consider the relationship between the views
The following diagram from the wikipedia article illustrates the views and relationships between them.
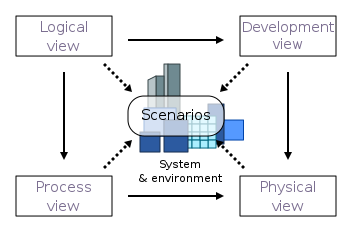
For any given system, you may not need to document all the views, and there may be other, more relevant views for your system. I recommend creating the minimal documentation to explain architectural decisions, and ensure you are ready and willing to evolve your architecture (in each of the views) as your solution matures.
Logical View
The logical architecture primarily supports the functional requirements — what the system should provide in terms of services to its users.

The logical view illustrates how the system is decomposed into specific areas of functionality. You will likely need to diagram the system at various levels of abstraction.
If you are using Domain-Driven Design (DDD) then at the highest level (the most abstract) you might show domains, sub-domains and bounded contexts and the flow of events between them. In the Domain Blue Book, this is called the 'context map'. At the lowest level (the most concrete), you might illustrate aggregates, aggregate roots, entities and relationships.
However, DDD is not the only way to design software - for some systems it may be better to illustrate functional modules, perhaps with a simple entity-relationship diagram.
Deep dive into the Logical View: coming soon...
Process View
The process architecture takes into account some non-functional requirements, such as performance and availability. It addresses issues of concurrency and distribution, of system’s integrity, of fault-tolerance, and how the main abstractions from the logical view fit within the process architecture [1]

The process view gets us to closer to an illustration of running software. Components in the process view are real executables that make up the run-time of your system.
For example, each of the following would be considered a 'process':
- IIS Web Application Pool
- Single-page app running in a browser
- Linux Daemon
- Database engine running stored procedures or SQL scripts
- etc.
Processes can be thought of as a unit of 'tactical control'. An individual process can be deployed, started, recovered, reconfigured, scaled out, and shutdown.
The purpose of the process view is to start to capture both the flow of inter-process information exchange (e.g. REST API calls, messaging via a bus) and the sequence and timing of these inter-process communications. This allows us to consider questions such as concurrency and reliability.
Deep dive into the Process View: coming soon...
Physical View
The physical architecture takes into account primarily the non-functional requirements of the system such as availability, reliability (fault-tolerance), performance (throughput), and scalability. The software executes on a network of computers, or processing nodes (or just nodes for short). The various elements identified — networks, processes, tasks, and objects—need to be mapped onto the various nodes. [1]

Even with the advent of Cloud computing and virtualised hardware, the physical architecture view still plays a critical role in understanding system performance and capacity.
Components are either processing nodes (servers, virtual machines, docker containers, serverless configurations, etc.) or networking channels (routers, firewalls, proxies, load balancers, etc.) and the diagram should illustrate which nodes host which processes from the process view. This allows us to start considering compute and network capacity, as well as latency and other performance considerations.
Deep dive into the Physical View: coming soon...
Development View
The development architecture focuses on the actual software module organization on the software development environment. The software is packaged in small chunks — program libraries, or subsystems — that can be developed by one or a small number of developers. [1]

I often think about the development view as the "source code" view. As such, you can consider it as having two 'sub-views', or perspectives:
- Physical perspective, comprised of:
- repositories
- file systems
- IDE projects/solutions & structure (e.g. Visual Studio Solutions)
The physical perspective helps you 'find' the code. There is a concept of 'nearness' which can be helpful when considering what code you want to keep 'near' what other code to enhance cohesion.
- Logical perspective, comprised of:
- modules (e.g. assemblies, packages)
- dependencies between modules
- layering of modules
The logical perspective helps you understand how the code modules work together. It allows you to understand static dependencies between the modules, as well as the flow of execution through the actual source code. This should help with understanding a run-time model - i.e. which modules will execute within which processes in the process view.
Deep dive into the Development View: coming soon...
Scenario/Use Case View
The elements in the four views are shown to work together seamlessly by the use of a small set of important scenarios —instances of more general use cases—for which we describe the corresponding scripts (sequences of interactions between objects, and between processes) [1]

The scenario, or 'use case' view helps tie the architecture together. Different diagrams help to illustrate the flow of activity in a system and illustrate which logical, process, physical and development components are working together to facilitate the outcome.
Deep dive into the Scenario/Use Case View: coming soon...
Why should I care?
In this series of posts, I hope to demonstrate that many challenges facing teams today are a consequence of blending and ignoring the distinctions between the views - trying to solve problems in one view with design patterns in a different view, or by tightly aligning the design in each view. My experience is that if you allow yourself to evolve your solution in each view independently, many of these challenges become much easier to reason about.
This means you can plan ahead to scale appropriately, you can more easily trace performance or scalability issues back to the source, and you can understand why different teams (owning different components in the development view) have complex developer-time interactions affecting autonomy and progress.
After exploring each of the views in depth in the coming posts, we'll return to this idea in more detail and explore how specific view alignment (or mis-alignment) patterns cause common risks and challenges.
